 |
Edinburgh Speech Tools
2.1-release
|


|
|
Edinburgh Speech Tools
2.1-release
|
|
Train n-gram language model
ngram_build [input file0] [input file1] ... -o [output file] [-p ifile] [-order int] [-smooth int] [-o ofile] [-input_format string] [-otype string] [-sparse ] [-dense ] [-backoff int] [-floor double] [-freqsmooth int] [-trace ] [-save_compressed ] [-oov_mode string] [-oov_marker string] [-prev_tag string] [-prev_prev_tag string] [-last_tag string] [-default_tags ]
ngram_build offers basic ngram language model estimation.
Input data format**:
Two input formats are supported. In sentence_per_line format, the program will deal with start and end of sentence (if required) by using special vocabulary items specified by -prev_tag, -prev_prev_tag and -last_tag. For example, the input sentence:
the cat sat on the mat
would be treated as
... prev_prev_tag prev_prev_tag prev_tag the cat sat on the mat last_tag
where prev_prev_tag is the argument to -prev_prev_tag, and so on. A default set of tag names is also available. This input format is only useful for sliding-window type applications (e.g. language modelling for speech recognition).
The second input format is ngram_per_line which is useful for either non-sliding-window applications, or where the user requires an alternative treatment of start/end of sentence to that provided above. Now the input file simply contains a complete ngram per line. For the same example as above (to build a trigram model) this would be:
prev_prev_tag prev_tag the prev_tag the cat the cat sat cat sat on sat on the on the mat the mat last_tag
Representation**:
The internal representation of the model becomes important for higher values of N where, if V is the vocabulary size, 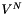 becomes very large. In such cases, we cannot explicitly hold probabilities for all possible ngrams, and a sparse representation must be used (i.e. only non-zero probabilities are stored).
becomes very large. In such cases, we cannot explicitly hold probabilities for all possible ngrams, and a sparse representation must be used (i.e. only non-zero probabilities are stored).
Getting more robust probability estimates**:
The common techniques for getting better estimates of the low/zero frequency ngrams are provided: namely smoothing and backing-off
Testing an ngram model**:
Use the ngram_test program.
 1.8.11
1.8.11